
Nearly any software platform you use performs its work based on algorithms, which enable it to make rapid decisions and respond predictably to stimuli. An algorithm is a step-by-step set of instructions for getting something done, whether that something is making a decision, solving a problem, or getting from point A to point B (or point Z). In this chapter, we will look into how computing algorithms work, who tends to create them, and how that affects their outcomes. We will also consider whether certain algorithms should be used at all.
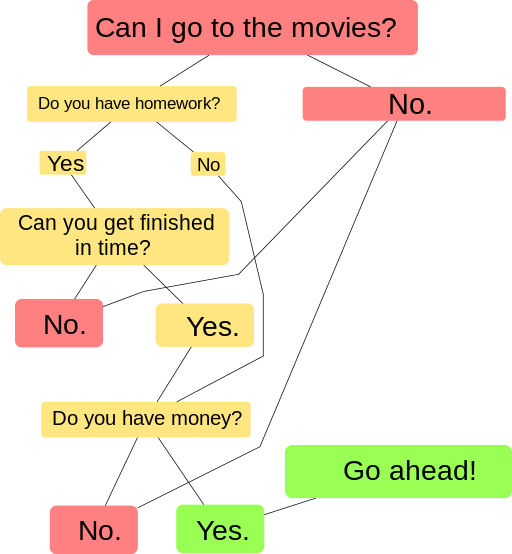
Section 1: Humans make computers what they are
Most platforms have many algorithms at work at once, which can make the work they do seem so complex it’s almost magical. But all functions of digital devices can be reduced to simple steps if needed. The steps have to be simple because computers interpret instructions very literally.
Computers don’t know anything unless someone has already given them instructions that are explicit, with every step fully explained. Humans, on the other hand, can figure things out if they skip steps, and can make sense of tacit instructions. But give a computer instructions that skip steps or include tacit steps, and the computer will either stop working or get the process wrong without human intervention.

Here’s an example of the human cooperation that goes into the giving and following of instructions, demonstrated with a robot.
As an instructor, I can say to human students on the first day of class, “Let’s go around the room. Tell us who you are and where you’re from.” Easy for humans, right? But imagine I try that in a mixed human/robot classroom, and all goes swimmingly with the first two [human] students. But then the third student, a robot with a computer for a brain, says, “I don’t understand.” It seems my instructions were not clear enough. Now imagine another [human] student named Lila telling the robot helpfully, “Well first just tell us your name.” The robot still does not understand. Finally, Lila says, “What is your name?”
That works; the robot has been programmed with an algorithm instructing it to respond to “What is your name?” with the words, “My name is Feefee,” which the robot now says. Then Lila continues helping the robot by saying, “Now tell us where you’re from, Feefee.” Again the robot doesn’t get it. At this point, though, Lila has figured out what works in getting answers from this robot, so Lila says, “Where are you from?” This works; the robot has been programmed to respond to “Where are you from?” with the sentence, “I am from Neptune.”
In the above example, human intelligence was responsible for the robot’s successes and failures. The robot arrived with a few communication algorithms, programmed by its human developers. Feefee had not been taught enough to converse very naturally, however. Then Lila, a human, figured out how to get the right responses out of Feefee by modifying her human behavior to better match the behavior Feefee had learned to respond to. Later, the students might all run home and say, “A robot participated in class today! It was amazing!” They might not even acknowledge the human participation that day, which the robot fully depended on.
Section 2: Two reasons computers seem so smart today
What computers can do these days is amazing, for two main reasons. The first is cooperation from human software developers. The second is cooperation on the part of users.
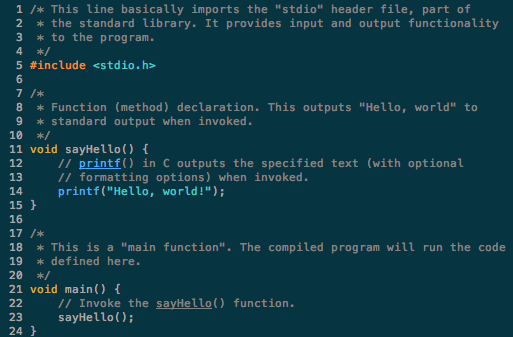
First, computers seem so intelligent today because human software developers help one another teach computers. Apps that seem groundbreaking may simply include a lot of instructions. This is possible because developers have coded many, many algorithms, which they share and reuse on sites such as GitHub. The more a developer is able to copy the basic steps others have already written for computers to follow, the more that developer can then focus on building new code that teaches computers new tricks. The most influential people known as “creators” or “inventors” in the tech world may be better described as “tweakers” who improved and added to other people’s code for their “creations” and “inventions.”
The second reason computers seem so smart today is because users are teaching them. Algorithms are increasingly designed to “learn” from human input. New algorithms automatically plug input into new programs, then automatically run those programs. This sequence of automated learning and application is called artificial intelligence (AI). AI essentially means teaching computers to teach themselves directly from their human users.
If only humans were always good teachers.
Student Insights: (Anti-)Social Media Algorithms (writing by Omar, Fall 2020)
Social Media During School

Respond to this case study: This writer used the research practice of observation to break down types of online spaces and practices. What are the benefits and challenges of drawing your knowledge about social media platforms from your own research? Demonstrate by studying the types of social media in your world.





{kind=link}
{kind=link}
{kind=link}